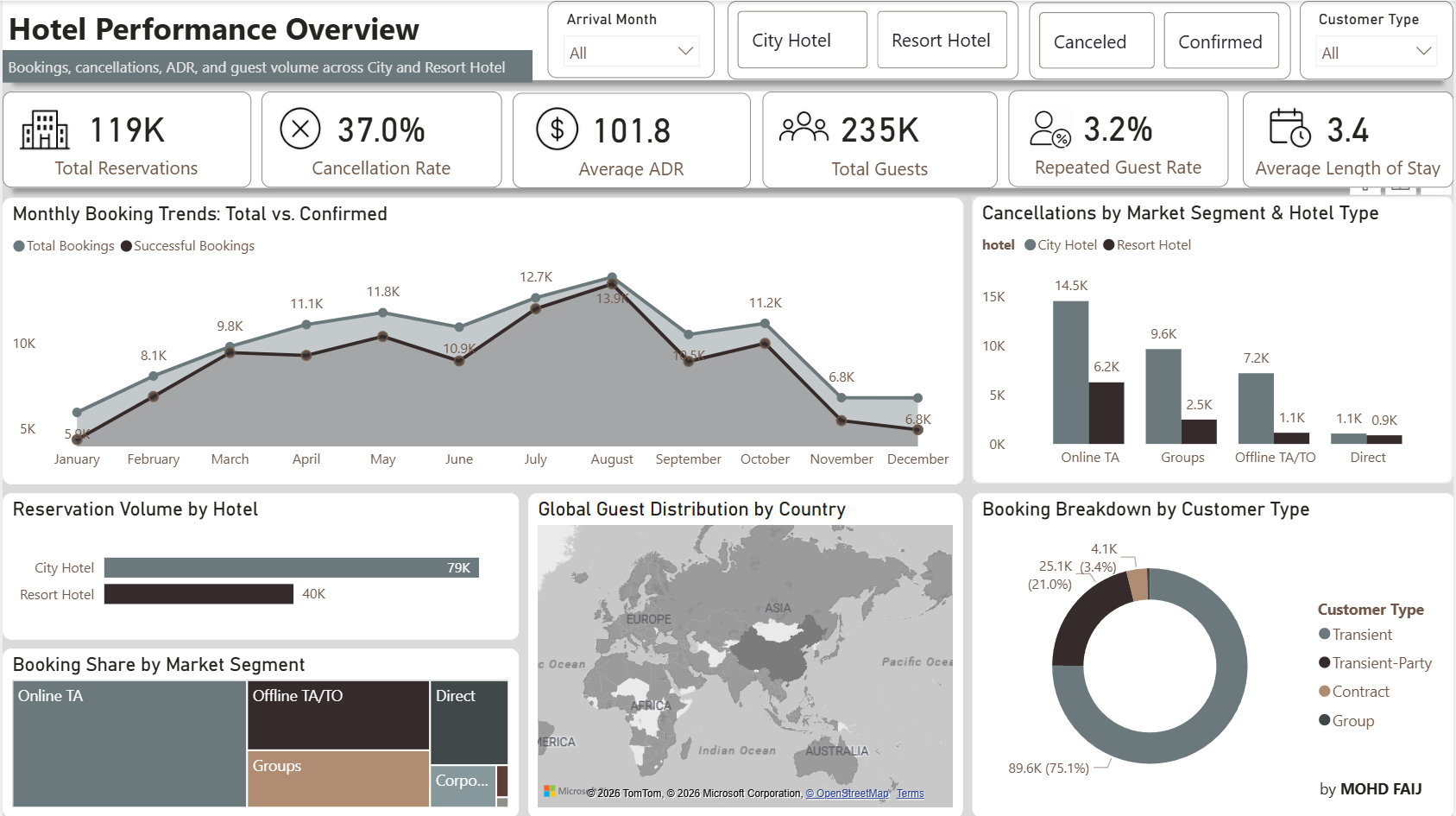
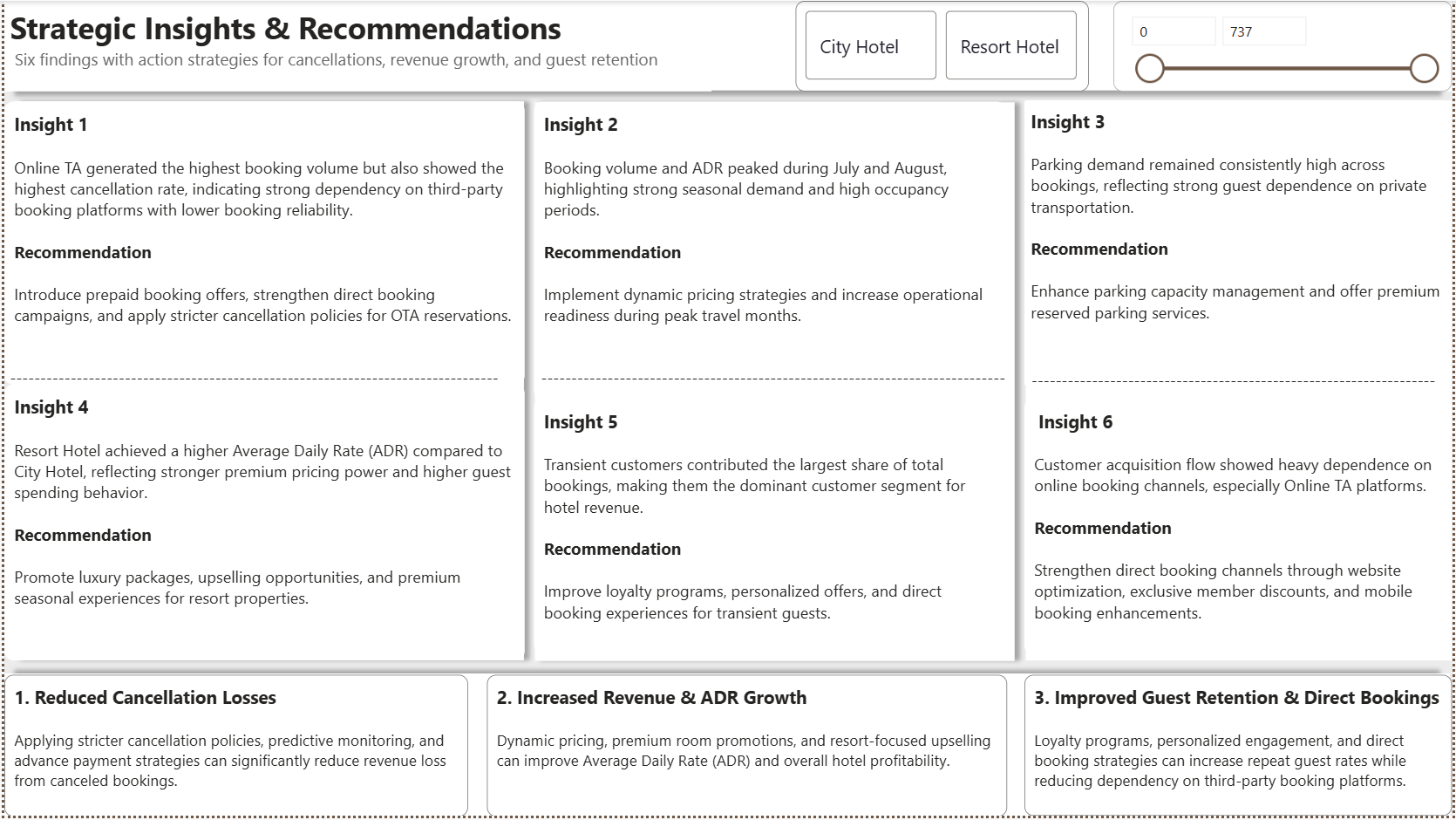
Transforming 119,400 raw hotel reservations into decision-grade revenue, cancellation risk, and guest retention intelligence — across City & Resort Hotel properties.
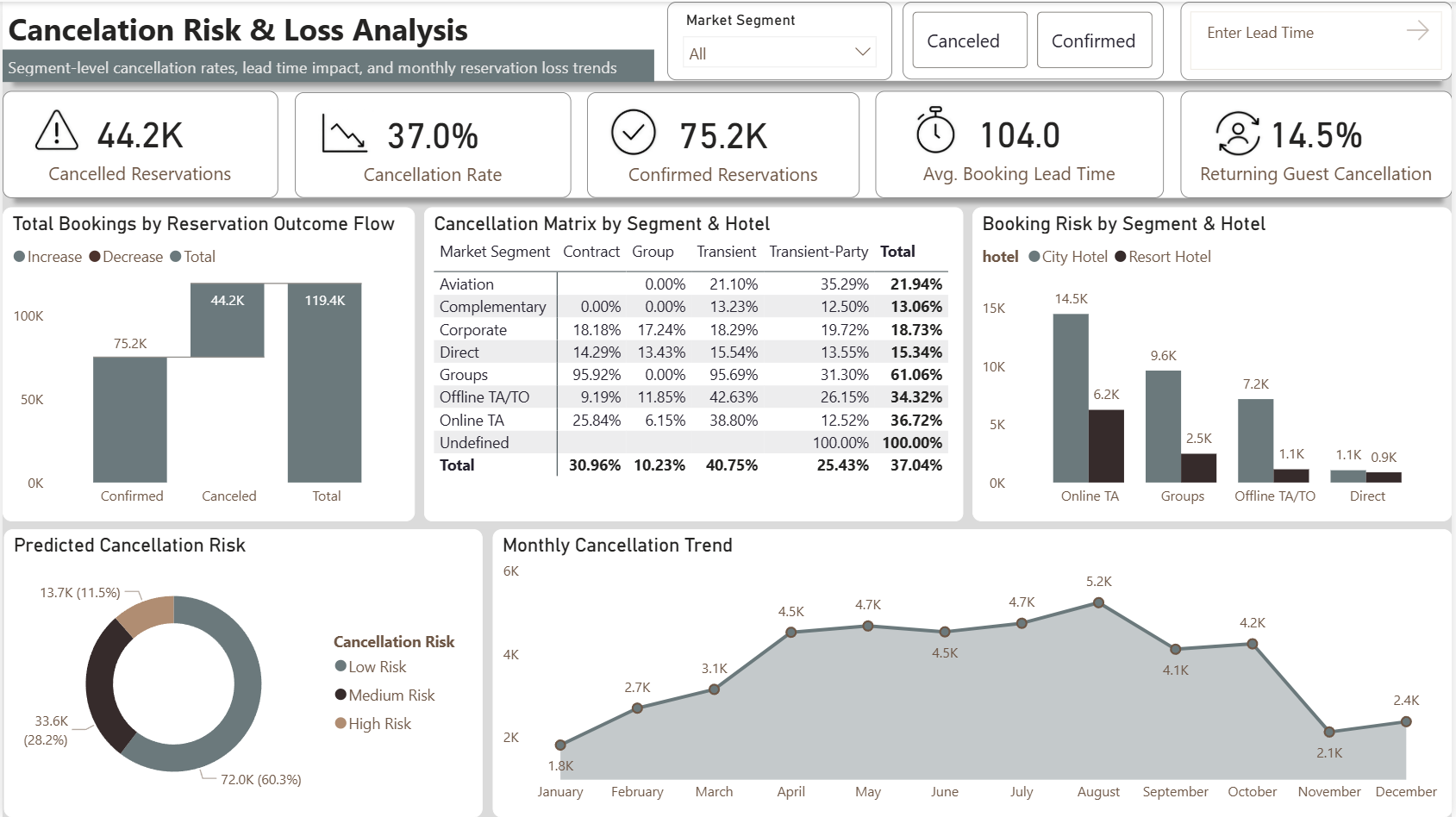
| Market Segment | Contract | Group | Transient | Transient-Party | Total |
|---|---|---|---|---|---|
| Aviation | — | 0.00% | 21.10% | 35.29% | 21.94% |
| Complementary | 0.00% | 0.00% | 13.23% | 12.50% | 13.06% |
| Corporate | 18.18% | 17.24% | 18.29% | 19.72% | 18.73% |
| Direct | 14.29% | 13.43% | 15.54% | 13.55% | 15.34% |
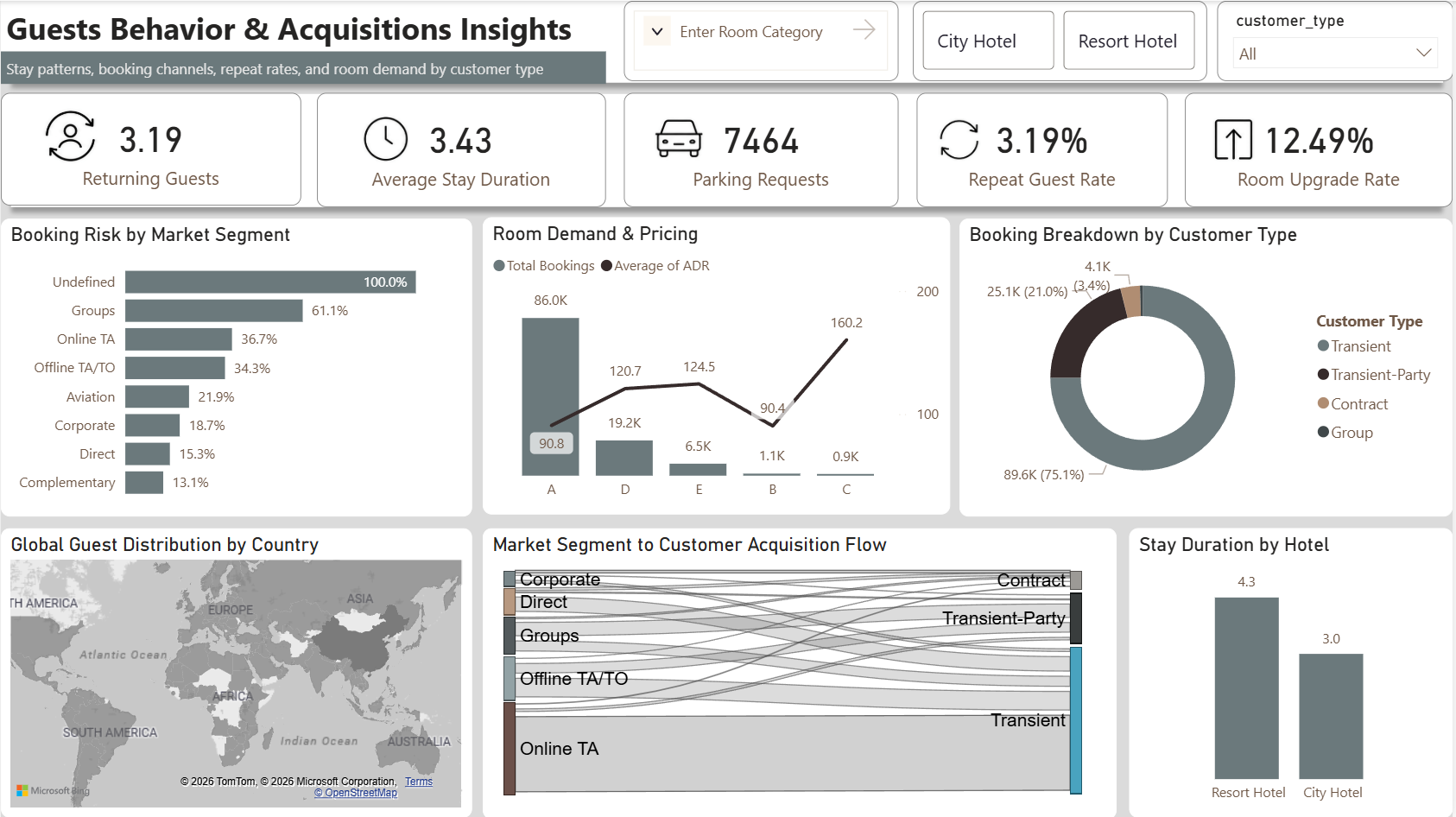
| Groups | 95.92% ⚠ | 0.00% | 95.69% ⚠ | 31.30% | 61.06% ⚠ |
| Offline TA/TO | 9.19% | 11.85% | 42.63% | 26.15% | 34.32% |
| Online TA | 25.84% | 6.15% | 38.80% | 12.52% | 36.72% ⚠ |
| TOTAL | 30.96% | 10.23% | 40.75% | 25.43% | 37.04% |
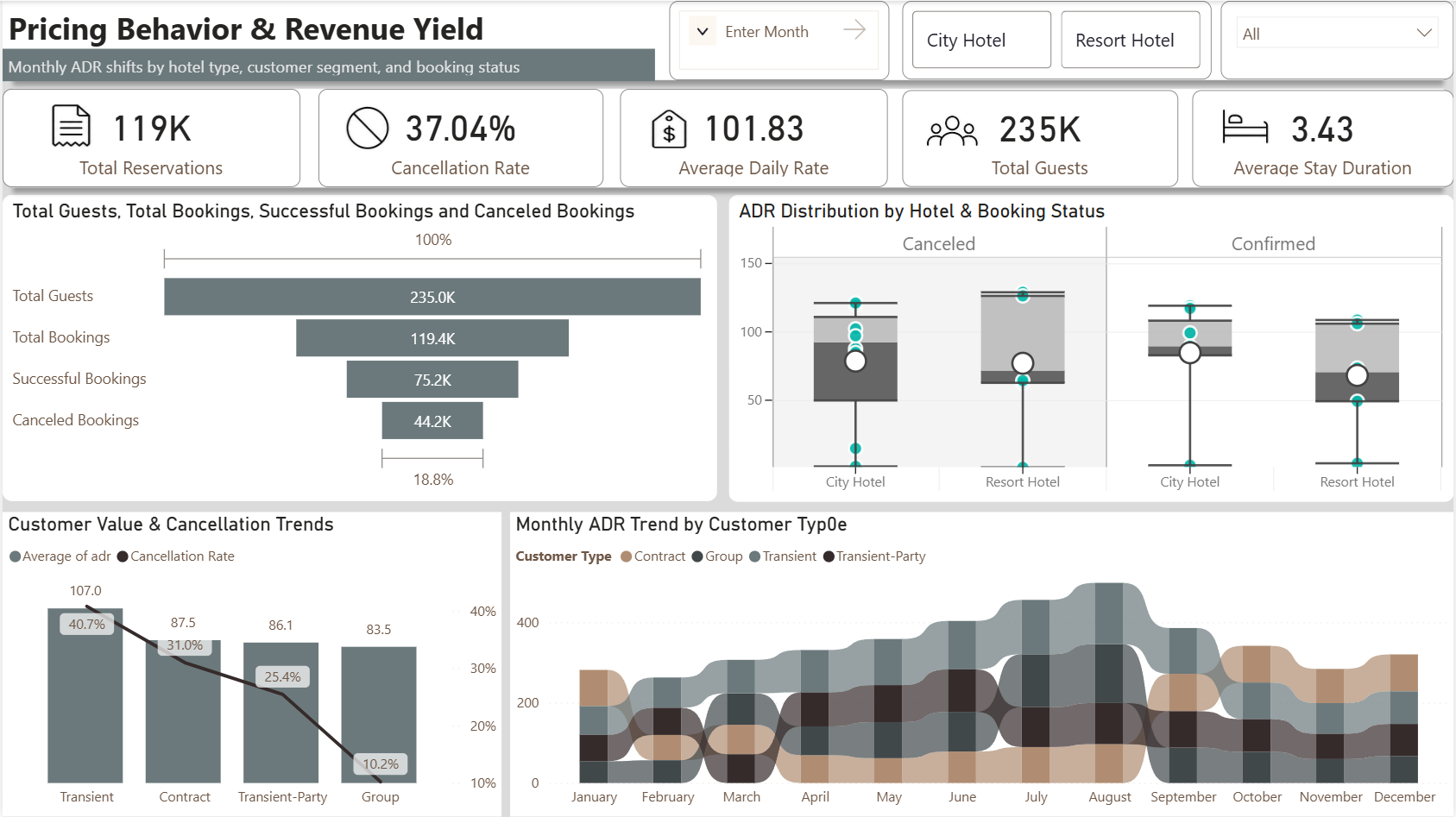
Transient guests pay the most ($107) but cancel the most (40.7%) — highest revenue risk segment.
High-Risk Triggers
Mandatory deposit request · Reduced cancellation window · Upsell to prepaid rate · Revenue team alert
13,700 high-risk bookings flagged at reservation time — enabling proactive revenue protection.
-- Cancellation rate per market segment SELECT market_segment, COUNT(*) AS total_bookings, SUM(CASE WHEN reservation_status = 'Canceled' THEN 1 ELSE 0 END) AS cancellations, ROUND( SUM(CASE WHEN reservation_status = 'Canceled' THEN 1 ELSE 0 END) * 100.0 / COUNT(*), 2 ) AS cancellation_rate_pct FROM hotel_bookings GROUP BY market_segment ORDER BY cancellation_rate_pct DESC;
-- Monthly ADR trend for City vs Resort Hotel SELECT hotel, arrival_date_month, ROUND(AVG(adr), 2) AS avg_adr, COUNT(*) AS total_bookings, SUM(CASE WHEN reservation_status = 'Canceled' THEN 1 ELSE 0 END) AS cancellations FROM hotel_bookings WHERE adr > 0 GROUP BY hotel, arrival_date_month ORDER BY hotel, FIELD(arrival_date_month, 'January','February','March','April','May','June', 'July','August','September','October','November','December' );
-- Market segment to customer type flow with risk scoring SELECT market_segment, customer_type, COUNT(*) AS total_bookings, ROUND(AVG(adr), 2) AS avg_adr, ROUND( SUM(CASE WHEN reservation_status = 'Canceled' THEN 1 ELSE 0 END) * 100.0 / COUNT(*), 2 ) AS cancel_rate, CASE WHEN AVG(lead_time) > 150 AND SUM(CASE WHEN reservation_status = 'Canceled' THEN 1 ELSE 0 END) * 100.0 / COUNT(*) > 40 THEN 'High Risk' WHEN SUM(CASE WHEN reservation_status = 'Canceled' THEN 1 ELSE 0 END) * 100.0 / COUNT(*) > 25 THEN 'Medium Risk' ELSE 'Low Risk' END AS risk_level FROM hotel_bookings GROUP BY market_segment, customer_type ORDER BY cancel_rate DESC;
-- Total Reservations Total Reservations = COUNTROWS('HotelBookings') -- Cancellation Rate Cancellation Rate = VAR _cancelled = CALCULATE( COUNTROWS('HotelBookings'), 'HotelBookings'[reservation_status] = "Canceled" ) RETURN DIVIDE(_cancelled, COUNTROWS('HotelBookings'), 0) -- Average Daily Rate (filtered for valid bookings) Avg ADR = CALCULATE( AVERAGE('HotelBookings'[adr]), 'HotelBookings'[adr] > 0 )
-- Predicted Risk Category (replicates ML output in DAX) Risk Category = VAR _leadTime = 'HotelBookings'[lead_time] VAR _prevCancel = 'HotelBookings'[previous_cancellations] VAR _depositType = 'HotelBookings'[deposit_type] VAR _segment = 'HotelBookings'[market_segment] RETURN SWITCH(TRUE(), _leadTime > 150 && _prevCancel > 0 && _depositType = "No Deposit", "High Risk", _leadTime > 80 && OR(_segment = "Online TA", _segment = "Groups"), "Medium Risk", "Low Risk" ) -- Revenue at Risk from High-Risk Bookings Revenue at Risk = CALCULATE( SUMX( 'HotelBookings', 'HotelBookings'[adr] * 'HotelBookings'[stays_in_week_nights] + 'HotelBookings'[adr] * 'HotelBookings'[stays_in_weekend_nights] ), [Risk Category] = "High Risk" )
-- Month-over-Month cancellation change Cancellations MoM % = VAR _currentMonth = CALCULATE( COUNTROWS('HotelBookings'), 'HotelBookings'[reservation_status] = "Canceled" ) VAR _prevMonth = CALCULATE( COUNTROWS('HotelBookings'), 'HotelBookings'[reservation_status] = "Canceled", DATEADD('DateTable'[Date], -1, MONTH) ) RETURN DIVIDE(_currentMonth - _prevMonth, _prevMonth, 0)
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # Load dataset df = pd.read_csv('hotel_bookings.csv') # Basic overview print(df.shape) # (119390, 32) print(df.isnull().sum()) # Check nulls # Cancellation rate by market segment cancel_rate = ( df.groupby('market_segment')['is_canceled'] .agg(['sum', 'count']) .assign(rate=lambda x: x['sum'] / x['count'] * 100) .sort_values('rate', ascending=False) ) print(cancel_rate) # ADR distribution by hotel type fig, ax = plt.subplots(figsize=(10, 5)) sns.boxplot( data=df[df['adr'] > 0], x='hotel', y='adr', hue='reservation_status', palette=['#4f46e5', '#ef4444'], ax=ax ) ax.set_title('ADR Distribution: Hotel × Booking Status') plt.tight_layout() plt.show()
# Feature engineering for ML model df['total_nights'] = ( df['stays_in_weekend_nights'] + df['stays_in_week_nights'] ) df['total_guests'] = ( df['adults'] + df['children'].fillna(0) + df['babies'] ) df['revenue_estimate'] = df['adr'] * df['total_nights'] # Encode categorical features from sklearn.preprocessing import LabelEncoder cat_cols = [ 'hotel', 'market_segment', 'customer_type', 'deposit_type', 'distribution_channel' ] le = LabelEncoder() for col in cat_cols: df[col + '_enc'] = le.fit_transform(df[col].astype('str')) # Select final features features = [ 'lead_time', 'adr', 'total_nights', 'total_guests', 'previous_cancellations', 'total_of_special_requests', 'booking_changes', 'hotel_enc', 'market_segment_enc', 'customer_type_enc', 'deposit_type_enc' ] X = df[features] y = df['is_canceled']
from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report, roc_auc_score import numpy as np # Train/test split X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y ) # Random Forest model rf = RandomForestClassifier( n_estimators=200, max_depth=12, random_state=42, class_weight='balanced' ) rf.fit(X_train, y_train) # Evaluate y_pred = rf.predict(X_test) y_prob = rf.predict_proba(X_test)[:, 1] print(classification_report(y_test, y_pred)) print(f"ROC-AUC: {roc_auc_score(y_test, y_prob):.4f}") # Assign risk tiers based on probability score df_test = X_test.copy() df_test['cancel_prob'] = y_prob df_test['risk_tier'] = pd.cut( df_test['cancel_prob'], bins=[0, 0.35, 0.65, 1.0], labels=['Low Risk', 'Medium Risk', 'High Risk'] ) print(df_test['risk_tier'].value_counts(normalize=True))
